This is my final blogpost, as my year as President of the Mathematical Association draws to a close, so I've allowed myself to go on at slightly longer length than usual. I wanted to conclude this series by thinking about problem solving, which for me is always the ultimate goal of learning mathematics. How can we help students not just to 'do problem solving' but actually learn to get better at it?
What I mean by problem solving
The term problem solving is used in different ways in different strands of the research literature (Note 1, see Foster, under review). Sometimes 'a problem' just means any mathematics question at all, such as a 'word problem', which might be an ordinary mathematics question dressed up in some 'real-life' context. But when I talk about a mathematics 'problem' I mean a non-routine task - in other words, a problem which the student doesn't have a ready-made method for solving - and this is the usual definition within the mathematics education literature. This means that whether something is a problem or not for any particular person depends on what methods they happen to have at their disposal at that particular time (see Foster, 2019, 2021).
The illustration that I like to use is of driving into a tunnel (Figure 1). Sometimes, before you enter a tunnel, you can see daylight out of the other side. The tunnel might still be quite long, but it is straight enough for you to see the entire route through before you begin. This is analogous to a routine task (Note 2), or exercise. Such tasks can be important for developing fluency with useful procedures - I am not saying 'routine is bad'. But with a routine task there is no challenge in deciding what to do, as that's clear from the outset.
The alternative scenario is a tunnel which you cannot see right through. You don't know before you enter if you will need to turn left or right - there might even be a dead-end and you could have to turn around and try a different approach. You might have some ideas for starting, but at the outset you don't know exactly how you're going to proceed - you will have to be flexible and respond to what happens; the first thing you try may not work. This is what I call a non-routine task, or problem.
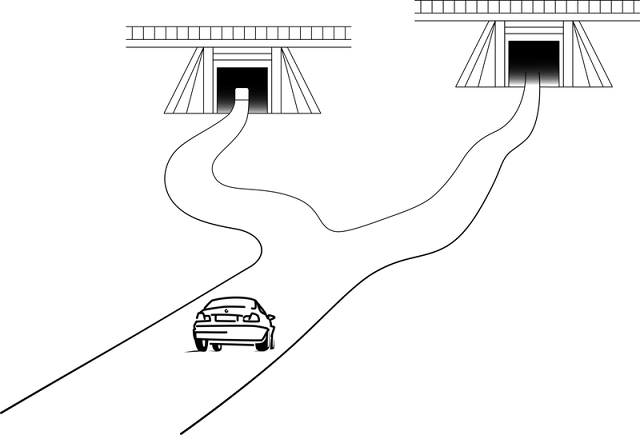 |
| Figure 1. A Routine task (left) versus a Non-routine task (right) |
It's important to realise that routine tasks are not necessarily quick and easy - they may be multi-step and require serious thought. When I say 'routine' I am not implying 'trivial'. For example, multiplying two 5-digit numbers together is a routine task for a mathematics teacher, because we know algorithms to use for this (whereas it wouldn't be for a child who hadn't learned a multiplication algorithm). However, even though a 5-digit by 5-digit multiplication is routine, I might easily make a mistake and get the wrong answer. But, even if I mess it up, it's still a routine task, because I know beforehand exactly how I should do it (Note 3).
So, if we accept that being able to tackle non-routine tasks (i.e., problems) is an important outcome of education, how do we help students get to the point where they are powerful problem solvers? It can't be enough simply to throw non-routine problems at them and watch them struggle. If we do that, a tiny minority may somehow discover the necessary problem-solving strategies to succeed, while the vast majority simply struggle to get anywhere and conclude that they must be not natural problem solvers. Instead, I think we need to explicitly teach these problem-solving strategies to everyone. But do these 'strategies' exist, and, if so, what are they?
A story about chess
When I was at primary school, my father taught me to play chess. What I mean is that he taught me the object of the game and the rules for how the pieces move. As far as either of us knew, that is what it meant to ‘learn chess’. I assumed that any further improvement would just come the more I practised, meaning the more games I played. At primary school, some children played chess at lunchtime, and I was considered to be good at chess, because I knew all the rules, and would try to think more than a move ahead, and anticipate what my opponent might do. With hindsight, I also suspect that people assumed I was good at chess because I was good at mathematics.
At secondary school, there was a chess club, which I joined, and, as before, I was one of the ones who knew the rules of chess, so I was treated as an expert, and I helped to teach others. We played in competitions against other schools, who had similar kinds of chess clubs, and sometimes we won games and sometimes they did – it was pretty random. Until one day we played against a local independent (private) school, and we all lost all our games within just a few minutes. What was going on? Were these ‘posh’ students just ‘clever’? Apparently the teacher who ran their chess club had played chess himself in national competitions, so perhaps that had something to do with it. Whatever the reason, we never lost against that school again - because we never played them again!
It wasn’t until I went to university, where nearly everyone had come from an independent school, that I discovered that people who had no interest in chess at all could beat me, which seemed very odd. I had assumed that those students in the chess team that beat us at school must have all been obsessively committed chess nerds, but actually I'm sure now that for most of them chess was just one of a hundred things they did fairly half-heartedly. The difference wasn’t, as we had assumed, that they had practised super-intensively, or were somehow smarter at thinking more moves ahead than we were. It was, of course, that they had been taught specific moves to use, and strategies for different points in the game (openings, endings, etc.), and had maybe even been shown some famous games. I had never realised that there were books about chess (e.g., Fischer, Margulies, & Mosenfelder, 1982) – and, if I had seen such books on the shelf, I would probably have assumed that they would not be interesting to me, and would be merely explaining the rules of the game, which I already knew. And if I had realised that such books taught strategies I might even have concluded that reading such a book was tantamount to cheating. You have to come up with your own moves, surely, otherwise that isn’t ‘playing the game’?
Teaching the rules but not the strategies
The reason for telling this story is that I think something a bit similar to this situation goes on in the teaching of mathematics in schools. Every teacher teaches students ‘the rules of the game’, such as that the angle sum of a plane triangle is $180^\circ$, and then we give students increasingly challenging problems to solve that depend on these rules. We might even tell ourselves that the problems “only require knowledge of” such-and-such short list of ‘angle facts’, and therefore that the students 'should' be able to solve them. When they get stuck, we might say, “Keep persevering – you know everything you need to know to solve it – you just need to keep thinking!” – but is that really true? This feels like saying that if you know the rules of chess then you know everything you need to know to win any game against any opponent, which I guess is what I thought as a child.
I began thinking back on all of this when I heard some teachers discussing what may be the most notorious example of a ‘hard but elementary’ angle problem. It is known as “Langley's Adventitious Angles”, and was posed by Edward Langley (Note 4) in The Mathematical Gazette in 1922. It involves what is sometimes referred to as the 80-80-20 triangle (see Figure 1). The task is to show that $x = 30$.
 |
| $ABC$ is an isosceles triangle. $B = C = 80^\circ$. $CF$ at $30^\circ$ to $AC$ cuts $AB$ in $F$. $BE$ at $20^\circ$ to $AB$ cuts $AC$ in $E$. Prove $BEF = 30^\circ$. Figure 1. Edward Langley’s original problem (Langley, 1922, p. 173). |
Since the problem was posed, over 40 different solutions have been produced (Chen, 2019; Rike, 2002; see also related problems in Leikin, 2001). However, most people find it extremely difficult to obtain a solution, and simply ‘angle chasing’ around, adding and subtracting angles, doesn't get you anywhere. On the other hand, the heavy machinery of things like trigonometry is not necessary either. So, this has been called “The World’s Hardest Easy Geometry Problem” – easy in the sense that it requires only elementary facts from geometry; hard because it’s extremely difficult to see how to use those elementary facts to solve it!
This raises the question 'Why is it that people can't solve this problem?' Similar questions are sometimes asked about the lovely geometry problems that Catriona Agg tweets (as @Cshearer41, see Shearer & Agg, 2019). I have heard plenty of highly competent mathematics teachers saying that, although they also really like her problems, they can't actually do them. So it's interesting to ask why not. Is it because the problems depend on knowledge of highly-advance geometrical theorems that these teachers have never studied? Of course not. All of Catriona's problems depend on simple school-level geometry - but they are hard nonetheless!
I think the missing ingredient is problem-solving tactics (finer grained than 'strategies'). Of course, content knowledge of geometry (e.g., the angle sum of a plane triangle is $180^\circ$) is essential. It is necessary but not sufficient. You can have encyclopaedic knowledge of all the geometry theorems in the world, but still be unable to apply them. So, I think success depends on having access to problem-solving tactics, and by this I don't mean high-level Polya-style generic strategies like 'draw a diagram' or 'be systematic'. Those are true, but hard to apply in any particular situation of being stuck (Schoenfeld, 1985). I mean much more topic-specific strategies (Foster, under review). In the case of Langley’s problem, the key strategy turns out to be to add an auxiliary line to the diagram, choosing the position wisely, so that it is parallel to a line that is already there, so creating corresponding or alternate angles or similar triangles (Note 5 - spoiler alert there!).
My recent Economic and Social Research Council (ESRC) project, Exploring socially-distributed professional knowledge for coherent curriculum design, carried out in collaboration with Professor Geoff Wake, Dr Fay Baldry and Professor Keiichi Nishimura in Japan, explored how the mathematics curriculum is designed and taught in Japan. In Japan, teachers explicitly teach problem-solving strategies, such as 'add an auxiliary line' (see Baldry et al., 2022). In the problem-solving strand of the LUMEN Curriculum resources, which we are currently designing at Loughborough University, the lessons explicitly and systematically teach problem-solving strategies like these, using problems which are dramatically unlocked by that strategy. The aim is for all students to build up a toolbox of these strategies, along with the knowledge of which one is likely to be useful for which problems. We are hoping that this will leave less to chance, and be a more effective way of helping all students become powerful problem solvers.
Concluding thoughts
Writing these 26 blogposts over the course of my year as President of the Mathematical Association has been a great pleasure, and I have particularly appreciated the many people who have got in touch with comments and reactions. Please continue to follow my work on Twitter @colinfoster77 and through my website https://www.foster77.co.uk/, and I hope to see many of you at the Joint Conference of Mathematics Subject Associations 2023 next week!
Questions to reflect on
1. Do you agree about the value of teaching problem-solving tactics, in addition to 'content'? Why / why not?
2. Where in your teaching/curriculum do students encounter strategies such as 'Draw in an auxiliary line'?
3. How might you plan to teach other problem-solving tactics explicitly?
Notes
1. I talked about many of the ideas in this post in my conversation with Ben Gordon on his podcast (BAGs to Learn Podcast by Ben Gordon, 2021).
2. I use 'task' to refer to anything mathematical a student is asked to do: it could be written, oral or practical.
3. It is actually a bit more subtle than this, because if the two 5-digit numbers that you asked me to multiply together happened to be, say, 11111 and 11111, then that might turn it into a non-routine task - i.e., a problem - because I might wish to avoid plodding through a standard algorithm and instead exploit the repdigit nature of these two numbers. However, on the other hand, if I had played around with such numbers before, I might know how strings of 1s behave when multiplied, and even know exactly how to write down the answer immediately, and so it would be back to being a non-routine exercise. So, whether something is routine or not depends in detail on what you happen to know.
4. Langley was the founding editor of The Mathematical Gazette. A curious fact is that he apparently had a blackberry named after him – not a lot of people can say that!
5. One possible solution is given in the diagrams below: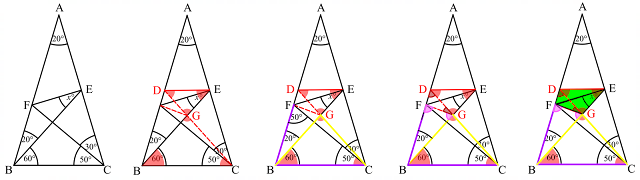
References
BAGs to Learn Podcast by Ben Gordon (2021, December 2). Episode 4 – Colin Foster – Problem Solving in the mathematics curriculum [Audio podcast]. https://anchor.fm/ben-gordon83/episodes/Episode-4---Colin-Foster---Problem-Solving-in-the-mathematics-curriculum-e1b5ic3
Baldry, F., Mann, J., Horsman, R., Koiwa, D., & Foster, C. (2021). The use of carefully-planned board-work to support the productive discussion of multiple student responses in a Japanese problem-solving lesson. Journal of Mathematics Teacher Education. Advance online publication. https://doi.org/10.1007/s10857-021-09511-6
Chen, Y. (2019). 103.39 A lemma to solve Langley’s problem. The Mathematical Gazette, 103(558), 521-524. https://doi.org/10.1017/mag.2019.121
Fischer, B., Margulies, S., & Mosenfelder, D. (1982). Bobby Fischer teaches chess. Bantam Books.
Foster, C. (2019). The fundamental problem with teaching problem solving. Mathematics Teaching, 265, 8–10. https://www.atm.org.uk/write/MediaUploads/Journals/MT265/MT26503.pdf
Foster, C. (2021). Problem solving and prior knowledge. Mathematics in School, 50(4), 6–8. https://www.foster77.co.uk/Foster,%20Mathematics%20in%20School,%20Problem%20solving%20and%20prior%20knowledge.pdf
Foster, C. (2023). Problem solving in the mathematics curriculum: From domain-general strategies to domain-specific tactics. The Curriculum Journal. Advance online publication. https://doi.org/10.1002/curj.213
Langley, E. M. (1922). Problem 644. The Mathematical Gazette, 11(160), 173. https://doi.org/10.2307/3604747
Leikin, R. (2001). Dividable triangles—what are they? The Mathematics Teacher, 94(5), 392-398. https://doi.org/10.5951/MT.94.5.0392
Quadling, D. A. (1978). Last words on adventitious angles. The Mathematical Gazette, 174-183. https://doi.org/10.2307/3616686
Rike, T. (2002). An intriguing geometry problem. Berkeley Math Circle, 1-4.
Schoenfeld, A. H. (1985). Mathematical problem solving. Elsevier.
Shearer, C. & Agg, K. (2019). Geometry puzzles in felt tip: A compilation of puzzles from 2018. Independent.