
Are there any 'boring' topics in mathematics? Understandably, mathematics teachers tend to be kind of professionally committed to the idea that all mathematics topics are interesting. If even the teacher doesn’t find the topic interesting, then what hope is there for the students? And yet, perhaps, if we are completely honest about it, we find some topics a bit harder to be enthusiastic about. For me, ‘rounding’ is that kind of a topic. But can it be made interesting?
I wonder if rounding is any mathematics teacher’s favourite topic? Somehow I doubt it, although perhaps, following this post, lots of people will write in the comments that it is theirs, which would be interesting! Even if it perhaps isn’t the most exciting topic, it’s certainly one that contributes to success in high-stakes assessments. Students will be repeatedly penalised throughout their examination paper if they don’t correctly round their answers to the specified degree of accuracy, so it’s certainly something that needs teaching. Boring but important?
When I suggest that rounding is not a very intrinsically interesting topic, I am not talking about ‘estimation’. That is certainly something that can be extremely interesting and engaging. I really like beginning with some scenario, such as a jar of sweets, and asking students for their off-the-top-of-their-head guesstimates of how many there are, and then coming up with a variety of different ways to improve on this (Note 1). Ideally this leads to the notion that quicker, rougher estimates are not necessarily ‘worse’ than more accurate ones, and choosing the optimal level of accuracy depends on the purpose for which you need the estimate and how much time you have available and how much effort seems worthwhile. Level of accuracy needs to be fit for purpose. A good way to promote this is to ask questions like:
- Which weighs more - a cat or 10,000 paperclips?
- Which mathematics teacher in our school do you think is closest to being a billion seconds old?
[Apologies, but I don't know where I first came across these examples - please say in the comments if there is someone I should acknowledge for these.]
In these, it is clear that your estimates only need to be accurate enough to answer the question. There is no point obtaining more accuracy than you need to do that.
But here I’m not thinking about contextual estimates like that but the more abstract kind of questions that you see in textbooks and on examinations, like:
Estimate the answer to $0.278 \times 73.4-\sqrt{48.3}$.
These questions that ask for ‘an estimate’ but don’t specify how accurate it should be are a bit nonsensical, it seems to me. You could always answer any question like this with ‘zero’, and the only hard part would be working out what degree of accuracy this was to (which the question never asks for). For example, the answer to this calculation turns out to be 13, to the nearest integer, so this would be 0 to the nearest 100, 0 to the nearest 1000, or (to be on the safe side) 0 to the nearest billion! Any point on the number line is always ‘close’ to zero if you zoom out far enough. So, you will technically never go wrong with a question like this by answering ‘0 to the nearest trillion’ – although of course mark schemes would not reward you for that!
More seriously, the usual approach that is taught within school mathematics is to round each individual number to 1 significant figure, with the possible exception of when you are about to find a root, where you might fiddle it to the nearest convenient number instead. So, in this example, although 48.3 would round to 50 to 1 significant figure, or 48 to 2 significant figures, we might instead choose to round it to 49, because $\sqrt{49}=7$. Doing that, we would get something we should be able to do easily in our head: $0.3×70-\sqrt{49}=21-7=14$.
The issue of how good our estimate might be (and therefore what it might be good for) is not really addressed at this level, and students would be expected simply to leave their answer as 14, without any idea how close this is likely to be to the true answer, or even whether it is an underestimate or an overestimate. But is this $14±1$ or $14±1000$ or what? This is really a bit strange, as, in any real situation, a lot of the value in estimating is in getting bounds. We may not care exactly what the answer is, but it is usually important to know that it is definitely between some number and some other number. Simply throwing back an answer like ‘14’, which we know is almost certainly not exactly right, without having any idea how wrong it is, doesn’t seem very useful. Usually, we are estimating a number in order to enable us to make some real-life decision – how much paint to buy, or how many coaches to order – and those all require us to commit to some actual quantity. So, really, I don’t want to know ‘roughly 14’ – I want to know ‘definitely between 10 and 20’ or definitely between 10 and 15. So perhaps we should teach it this way? (Note 2)
Then, we can consider that how much effort it is worth going to in order to get a more accurate estimate depends on how narrow I want my bounds to be. It’s foolish to act as though more accuracy is simply an absolute good. (Sitting down and calculating more and more digits of $\pi$ forever would not serve any useful purpose.) Sometimes, when peer marking, students will be told to give themselves more marks if their answer is closer to the ‘true’ answer, but I think this reinforces an unhelpful view of estimation. It also encourages students to 'cheat', by first calculating the exact answer, rounding this answer, and then constructing some fake argument for how they legitimately got it. If more accuracy were always better, we would always use a calculator or computer and get the answer to as high a degree of accuracy as we possibly could. But, with estimation, the sensible thing to do is to spend your effort according to how useful any extra accuracy would be in the particular context that applies. These seem to me the important issues in estimation, and they go largely unaddressed in the lessons on estimation that I see.
Exploring rounding
One way to make the topic of ‘rounding’ a bit more interesting is to begin to explore some of these issues. For example, in the calculation above, since (almost) all of the numbers were rounded to 1 significant figure, it might seem sensible to give the answer to 1 significant figure, which would be 10, suggesting that this means $10±5$. In this case, the exact answer to the original calculation (13.45537…) is also 10, to 1 significant figure, which is good, and there seems to be an assumption within school mathematics that almost has the status of a theorem:
Claim 1: If you round each number in a calculation to 1 significant figure, then the answer will also be correct to 1 significant figure.
However, there is no reason at all why this should be true, and you might like to consider what the simplest counterexample is that you can find. When can you be more confident using this heuristic, and when should you be more cautious?
***
A simple counterexample would be $3.5+3.5$, which comes to 8 if you round each of the 3.5s to 4 (to 1 significant figure) before you add them, but 8 is not the correct answer to 1 significant figure, because of course it should be 7.
A slightly more complicated scenario that might be worth exploring with students involves rounding two numbers in a subtraction, so we could begin with a question like this:
Estimate the answer to $14.2-12.9$.
(You might ask, "Why estimate something so simple, and not just calculate?", and the point of this is not to be a realistic rounding scenario, but a simplified situation to help us see what is actually going on with rounding.)
So, here's another claim:
Claim 2: If we round each number to the nearest integer, then the answer will be correct to the nearest integer.
Is this claim always, sometimes or never true?
Students will need a bit of time to figure out what the claim even means. Using the notation $[x]$ to mean “round $x$ to the nearest integer”, we could write:
$[14.2]-[12.9] = 14-13 = 1$
And $[14.2-12.9] = [1.3] = 1$.
So that checks out in this case.
So, in this notation, the question is:
When is $[a-b] = [a]-[b]$?
I think this is a potentially interesting task, where there is plenty to think about, but it also generates some repetitive but somehow acceptable routine practice. (I call such tasks mathematical etudes – see Foster, 2018). You might like to try it yourself before reading on.
***
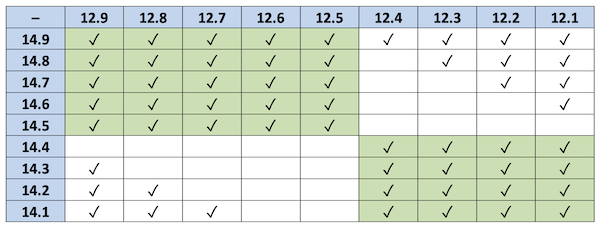 |
| Table 1. $[14.x-12.y]$ and $[14.x]-[12.y]$ compared, where $x$ and $y$ are single digits between 1 and 9. Ticks indicate where equality holds. |
So, a counterexample to Claim 2 would be any of the empty cells in this table; for example, $[14.7-12.3] = [2.4] = 2$ but $[14.7]-[12.3] = 15-12 = 3$.
We might prefer to write this on one line as:
$$3 = 15-12 = [14.7]-[12.3] ≠ [14.7-2.3] = [2.4] = 2$$
Applying some deduction, we might say:
1. If both numbers in the subtraction are rounded up, or both are rounded down, we should get a tick. These are the ticks in the green squares in the table above.
We might also be tempted to say:
2. If one number is rounded up and the other number is rounded down, we should not get a tick.
As you can see from Table 1, this is false, as can be seen by the ticks in some of the white squares. Why does this happen? For example, in $14.3-12.8$, the minuend rounds down and the subtrahend rounds up, and we get no tick, since the difference, 1.5, rounds up to 2, whereas $14-13 = 1$. However, this doesn’t always happen. For example, in $14.2-12.8$, as before, the minuend rounds down and the subtrahend rounds up, giving $14-13 = 1$, but this time the difference is only 1.4, which rounds down to 1, so we do get a tick.
There is lots to explore here, and the idea of comparing the result from applying some function before and after some composition - i.e., $f(x \pm y) \stackrel{?}{=} f(x) \pm f(y)$ - is a highly mathematical question.
When I look back at mathematics tasks that I have designed over the years, I now notice that they often cluster around certain ‘favourite’ topics. Without meaning to, I have unintentionally avoided certain topics – perhaps those that, like ‘rounding’, seem intrinsically less interesting – and cherrypicked other topics to design tasks for. At Loughborough, we are currently working on designing a complete set of teaching materials for Year 7-9, so we are now working in the same kind of situation as teachers – we can’t miss anything out! And this has led me to thinking about how to address some of those potentially ‘less interesting’ topics, which is proving fun.
Questions to reflect on
1. Are there mathematics topics that you personally find less interesting to teach? Which ones? Why?
2. What tasks can make these topics more interesting for you and for your learners?
3. For rounding, what other tasks can you devise? Is $[a+b] \stackrel{?}{=} [a]+[b]$ an easier or harder problem? What about $[ab] \stackrel{?}{=} [a][b]$?
Notes
1. Dan Meyer is the expert at designing tasks like this; e.g., https://blog.mrmeyer.com/2009/what-i-would-do-with-this-pocket-change/; https://blog.mrmeyer.com/2008/linear-fun-2-stacking-cups/; https://www.101qs.com/70-water-tank-filling
2. I think the various versions of the “approximately-equal sign” $≈$ are not really our friends here, because a statement like $13≈10$ doesn’t really have a precise meaning.
References
Eastaway, R. (2021). Maths on the back of an envelope: Clever ways to (roughly) calculate anything. HarperCollins.
Weinstein, L., & Adam, J. A. (2009). Guesstimation. Princeton University Press.
Weinstein, L. (2012). Guesstimation 2.0. Princeton University Press.


No comments:
Post a Comment